AI의 꽃 자연어 처리, 플랫폼 경쟁 치열

인공지능(AI)이 자연어처리(NLP) 기술을 만나 꽃을 피우고 있다. 구글, 마이크로소프트(MS), IBM 등 글로벌 기업은 물론 네이버 등 국내 기업들까지 NLP 기술을 이용한 AI 서비스를 속속 선보이고 있는 상황이다. AI 서비스 전쟁의 이면에 NLP 경쟁이라는 전투가 벌어지고 있는 것이다.
NLP 부문의 승자가 AI 서비스의 주도권을 쥘 것으로 예측된다. 손자병법에는 ‘적을 알고 나를 알아야’ 승리할 수 있다고 했다. 그 어느 때보다 NLP를 제대로 알고 미래 방향을 예측하는 것이 중요해 졌다.
자연어 처리(Natural Language Processing)는 자연어를 기계적으로 분석해 컴퓨터가 이해할 수 있는 형태로 만들거나 또는 컴퓨터의 처리 결과를 인간이 이해할 수 있는 언어로 만드는 기술이다.
인공지능 서비스 발전에 NLP는 중요한 부분이다. 인공지능은 사용자의 명령을 수행한다. 바로 그 명령을 인식하도록 해주는 기술이 NLP이다. 최근 수년간 국내외 기업들은 NLP 적용 서비스를 잇따라 선보이고 있다.
국내외 AI NLP 서비스 확산
인공지능 알파고(AlphaGo)로 센세이션을 일으켰던 구글의 사례를 보자. 구글은 최근 ‘구글 I/O 2016’ 행사에서 집주인 음성을 알아듣고 지시를 수행하는 가정용 스마트 스피커인 ‘구글 홈’을 발표했다.
또 구글은 2016년 5월 18일 AI 비서 ‘구글 어시스턴트’를 공개했다. 이 서비스는 머신러닝을 통해 음성인식의 정확도를 크게 개선했으며 사용자 간 대화의 맥락을 이해해 실시간 답변을 지원한다.
구글은 카메라로 비추는 언어를 즉시 번역해주는 번역 앱인 워드렌즈의 서비스를 2011년 개발한 후 확대 중이다. 구글 워드렌즈는 중국어를 포함해 29개 언어를 지원하고 있으며 현재 5억 명 이상이 사용 중이다.
인공지능 플랫폼 왓슨(Watson)으로 구글과 경쟁하고 있는 IBM도 왓슨 응용애플리케이션인터페이스(API)를 통해 번역, 문맥분석, 음성인식, 이미지 인식 기능을 제공한다.
IBM 왓슨 개발자 클라우드(Watson Developer Cloud)는 머신러닝 기술을 기반으로 언어 구조를 인식, 애플리케이션으로 하여금 음성 명령을 인식할 수 있게 하는 서비스인 ‘스피치 투 텍스트(Speech to Text)’와 텍스트를 음성으로 변환시키는 기능을 제공한다.
세계 최대 소프트웨어(SW) 기업인 마이크로소프트(MS) 역시 2014년 4월 인공지능 소프트웨어로 음성 비서 서비스를 제공하는 가상 비서 ‘코타나’를 선보였다.
또 MS는 언어를 실시간 통역, 번역해주는 스카이프 트랜스레이터(Skype Translator)도 2014년 공개한 바 있다. 이 서비스는 일대일 스카이프 영상, 음성통화 통역, 통화 시 화면에 변역문을 표시, 저장해준다.
일본 소프트뱅크는 2014년 6월 공개한 AI 로봇 페퍼에 사람의 표정과 목소리를 인식하고 감정을 표현하는 이모셔널 엔진(Emotional Engine)과 통신기능을 탑재했다.
애플도 2011년 10월 아이폰4S에 ‘시리(Siri)’를 탑재하기 시작했다.

| (시기별 자연어 처리 번역과 대화형 서비스 내용) |
국내 기업, 기관들의 움직임도 활발하다.
2016년 3월 네이버는 대화형 인공지능 라온(LAON) 서비스를 공개했다. 네이버는 올해 상반기에 본격적인 서비스를 제공할 방침이다. 네이버는 보유한 방대한 데이터 알고리즘을 라온 서비스에 적극 활용할 전망이다.
솔트룩스는 2016년 2월 인간의 언어를 이해할 수 있는 차세대 인공지능 ‘아담’을 개발했다. 아담은 인터넷을 통해 데이터를 수집, 학습하며 축적된 학습 데이터를 일반 클라우드 서버에서 처리한다. 초당 질의 처리가 1600개까지 가능하며 초당 70만개 단위 지식을 추론할 수도 있다.
NLP 부문의 벤처기업인 시스트란은 50개 이상의 언어, 140개 이상의 언어쌍에 대한 기계번역을 RBMT와 SBMT를 결합한 하이브리드 번역엔진(HMT)을 통해 제공한다. 시스트란은 2016년 4월 지능형 언어처리 솔루션 ‘SYSTRAN.io’를 공개한 바 있다.
한국전자통신연구원(ETRI)은 2013년부터는 시스트란과 함께 삼성 갤럭시S4 등 프리미엄급 스마트폰에 ‘지니톡’ 한/영, 한/중 자동번역 기술을 공급해 220만 다운로드를 기록했다.
NLP 서비스가 다양해 지는 만큼 시장도 급성장할 전망이다.
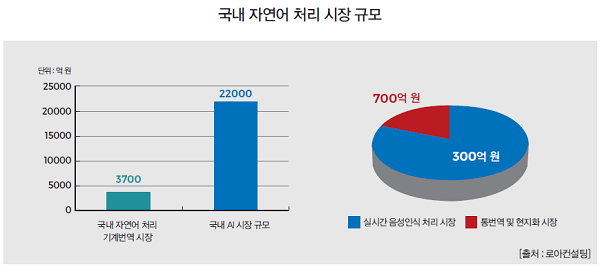
정보기술연구기관인 윈터그린 리서치에 따르면, 세계 자동번역 솔루션 시장은 2012년 16억 달러(약 1조6260억원)에서 2019년에는 69억 달러(약 7조원)로 급성장할 전망이다. 2015년 통·번역 관련 글로벌 SW 시장은 약 5조원이며 국내 통·번역 및 현지화 시장은 500억원 규모다.
KT 경영경제연구소에 따르면 2020년 국내 AI 시장 규모는 약 2조 2000억 원 수준에 달할 것으로 예상 된다. 국내외 자료에 기초해 다양한 산업군으로 적용될 것을 가정, 산출해보면 국내 자연어 처리 기계번역 시장 규모는 2020년 약 3700억 원에 이를 것으로 예측된다.
NLP 시장의 미래
이렇게 급성장하고 있는 NLP 시장은 어떤 모습으로 진화할까.
우선 번역의 질을 높이기 위해 빅데이터 기반의 말뭉치(Corpus)를 수집하고 머신러닝을 이용해 번역품질을 개선하기 위한 노력이 이뤄질 것이다. 자연어 처리는 원래 검색의 효율성을 높이기 위해 사용됐다.
이후 구글이나 아마존 등이 링크를 통해 누가, 얼마나 접속했는지 관심을 가지며 정보접근을 개선하려는 움직임이 일자 기업들은 저마다 자신의 애플리케이션을 지능적으로 만들기 위해 머신러닝과 심화 텍스트 분석을 적용했다.
이를 통해 애플리케이션은 대량의 데이터를 다룰 수 있게 됐다. 기업은 중요한 텍스트 특성을 추출하고 사용자 클릭, 평점, 평가 같은 정보를 모으며 유사한 콘텐츠를 분류하고 요약하는 데 주력해 사용자에게 더 나은 사용자경험(User Experience)을 제공한다.
자연어 대화형 서비스의 출현과 음성인식 정확도 개선을 위한 자동음성인식(ASR) 기술의 진보도 예상된다.
자연어 처리 기술은 텍스트 중심에서 비디오나 이미지의 텍스트 변환으로 바뀌고 있다. 키보드를 통한 검색은 컴퓨터가 패턴인식과 NLP를 수행할 수 있게 되면서, 이를 기반으로 무수히 많은 응용 작업이 가능해졌다.

| (NLP 플랫폼 구조도) |
이에 OCR(Optical Character Reader)을 통해 이미지를 인식, 입력하는 방식이 등장해 다양한 사진에서 같은 사람이 찍힌 사진을 분류, 사물과 배경의 이름을 부여하는 자동 라벨링 작업이 가능해졌고, 음성인식 기술과 자연어 처리 기술이 결합해 ASR(Automatic Speech Recognition) 기술을 활용, 음성(Voice)을 자동으로 입력하는 방식을 통해 인간의 말을 알아듣고 반응할 수 있는 인공지능 서비스 개발이 가능해졌다.
NLP 플랫폼 경쟁
중요한 변화 중 하나는 NLP 공개 플랫폼이다. 앞으로 NLP 공개 플랫폼을 통한 생태계 구성과 이를 둘러싼 글로벌 플랫폼 사업자 간 경쟁이 심화될 수 있다.
구글은 오픈 소스 공개로 개발자들이 정확한 명령어 입력에 들이는 수고를 덜게 해 자연어 이해생태계를 확산시켰다. 2015년 11월에는 신경망 기반의 NLP 플랫폼 ‘신택스넷(SyntaxNet)’을 공개했다. 신택스넷은 자연어 이해 시스템의 일부로 텍서플로우 기술을 활용했다.
IBM은 AI 시스템 왓슨을 기반으로 한 플랫폼을 공개하고 있다. 또 네이버는 2016년 1월부터 이용자가 직접 영어 예문으로 번역 가능한 NLP 공개 플랫폼인 이용자 참여 번역 서비스를 운영하고 있다.
시스트란의 사례도 주목된다. 올해 4월에는 자동번역 기술과 자연어 처리 기술을 개방형 오픈 API로 제공하는 NLP 공개 플랫폼인 SYSTRAN.io을 출시했다. 공개 플랫폼인 SYSTRAN.io을 통해 개발자들은 운영체제(OS)의 제약 없이 다양한 제품에 자연어 처리 기능을 구현하는 것이 용이하게 됐다.
이 업체는 NLP 플랫폼 생태계의 성장을 위해 강점을 보여오던 기업(B2B), 개인(B2C) 고객 외에도 개발자(B2D) 중심의 시장도 집중 공략할 예정이다.
이처럼 기업들은 플랫폼을 중심으로 개발자와 고객이 양면시장을 이루고 번역 API를 무료로 공개해 자사의 기계번역 기술을 활용한 커뮤니케이션 이용자를 끌어 모으기에 주력하고 있다.
번역 공개 플랫폼이 양면시장 중 한 쪽의 고객 임계점을 돌파해 네트워크 효과를 일으키게 된다면 API를 탑재한 제품과 서비스는 더욱 많은 사용자와 사용횟수를 얻을 수 있다. 이를 통해 번역엔진 훈련을 위한 대량의 고객 사용 데이터 확보할 수 있는 것이다.
훈련 데이터를 통해 강화된 번역엔진은 정확도와 오류도 개선시켜 번역 품질의 수준을 높여준다. 그리고 기능이 강화된 API가 탑재 된 어플리케이션이 더욱 많이 출시될 것이다. 이런 선순환을 통해 번역 기업들은 시장 지배력을 강화하고, 나아가 공개 플랫폼을 통한 자사 중심의 NLP 생태계 조성을 목표하고 있다.
플랫폼 공개 전략은 번역 산업 분야 이외에도 기업들의 해외 현지화 시장 및 여행, 관광, 교육 등 다양한 분야에 접목이 가능해 이종산업간의 플랫폼 경쟁으로의 확대가 예상된다.
AI가 발전하기 위해서는 NLP 발전이 꼭 필요하다. 사용자들이 불편하게 느끼는 서비스는 살아남을 수 없다. 반대로 사용자들이 손쉽게 이용할 수 있는 서비스는 살아남는다.
AI 서비스를 쉽게 이용할 수 있도록 해주는 것이 바로 NLP다. NLP가 없는 AI 서비스는 ‘앙꼬 없는 찐빵’과 같다. 아무리 AI 기능이 뛰어나도 이용하기 불편하다면 사람들은 AI를 사용하지 않을 것이다.
AI 시대를 준비해야 한다는 목소리가 높다. 차세대 성장동력으로 AI를 꼽는 전문가들도 많다. 기업들은 물론 정부도 AI 기술 발전과 관련 서비스 확산이 필요하다고 지적하고 있다. AI 시대를 준비하기 위해서는 NLP가 중요하다. NLP를 제대로 알고 활용해야 AI 시대에 살아남을 수 있을 것이다.
현존 최고의 자연어처리 인공지능 선발대회

인터넷에서 사람과 인공지능(AI)의 논쟁이 벌어졌다. 주인공은 데이빗 샬머스 미국 뉴욕대 철학과 교수와 여러 언론에서 ‘현존 최고의 자연어처리 AI’라고 평가받고 있는 GPT-3였다. 샬머스 교수는 ‘GPT-3는 의식이 있을 것’이라고 의혹을 제기했지만, GPT-3가 ‘나는 의식도 없고 즐거움과 고통도 못느낀다’고 반박하면서 논쟁은 마무리됐다. 이 논쟁을 통해 인간과 가장 비슷한 언어를 구사할 수 있는 AI인 GPT-3의 진면목이 드러났다는 평이 나왔다. 하지만 GPT-3가 엄밀한 의미에서 가장 뛰어난 자연어처리 AI는 아니다. GPT-3 외에도 뛰어난 성능을 보이는 AI가 여럿 나와 최고의 자연어처리 AI 왕좌를 놓고 경쟁 중이다.
미국 비영리연구소 오픈AI에서 개발한 GPT-3는 ‘자연어처리 인공지능(AI)’이다. 자연어는 한국어, 영어처럼 사람들이 사용하는 언어다. 자연어처리 AI는 자연어를 이용해 사람과 대화를 하거나, 소설이나 신문기사 등의 문장을 만들어내는 AI를 뜻한다.
자율주행부터 의료, 보안 등 실생활의 다양한 분야에서 자연어처리 AI의 역할이 점점 커지고 있다. 궁극적으로 AI가 우리 실생활에 더 가까이 다가오기 위해서는 사람과의 의사소통이 가능해야 한다.
AI를 개발하는 전문가들은 C, 자바(JAVA), 파이썬(Python) 같은 컴퓨터 언어를 사용한다. 하지만 모든 사람이 AI와 의사소통을 하기 위해 컴퓨터 언어를 공부할 수 없는 노릇이다. 이 때문에 자연어처리 AI가 등장했다.
원래 AI는 사람 수준으로 자연어를 이해하고 구사하기는 어렵다. 자연어와 컴퓨터 언어에는 큰 차이가 있기 때문이다. 가장 큰 차이는 ‘문맥’의 이해 여부다. 문맥은 단어 또는 문장의 앞뒤 상황에 따라 나타나는 언어적인 맥락이다. 같은 단어나 문장이라도 문맥에 따라 그 의미가 다르게 사용될 수 있는 요소를 말한다. 예를 들어 ‘잘했네, 잘했어’라는 문장을 보자. 어떤 행동을 정말 잘했다는 의미일 수도 있지만, 만약 앞서 잘못을 지적하거나 누군가 실수한 상황이라면 반대로 질책하는 의미가 될 수도 있다. 이 때문에 자연어는 문맥에 따라 의미가 바뀔 수 있는 ‘문맥 의존 언어’로 분류된다.
반면 컴퓨터 언어는 앞뒤 문맥과 관련 없는 명확한 표현만이 가능하다. 이를 ‘문맥 자유 언어’라고 부른다. 바로 이점이 AI가 자연어를 처리하는 데 가장 어려움을 겪는 부분이다.
물론 문맥에 대한 의존성만이 자연어처리의 장벽은 아니다. 강승식 국민대 소프트웨어융합대 교수는 “언어는 사회문화에 따라 의미가 변형되기도 하고, 새로운 단어가 만들어지거나 기존의 단어가 사라지기도 한다”며 “이 때문에 자연어처리 AI를 학습시키기 위해서는 수많은 데이터가 필요하다”라고 말했다. 만약 이런 데이터를 확보하지 못하거나 완벽히 학습시키지 못한다면 자연어처리 AI의 성능을 향상시키기 어렵다.
자연어처리 AI 3파전

현재 가장 뛰어난 성능을 가진 자연어처리 AI 모델로는 미국 정보통신(IT) 기업 구글에서 개발한 트랜스포머(Transformer)와 버트(BERT), 그리고 GPT-3가 꼽힌다.
세 종류의 AI 중 가장 먼저 개발된 모델인 트랜스포머는 2017년 공개됐다. 트랜스포머 모델이 발표되기 이전에는 자연어처리 AI 대부분이 전통적인 방식의 딥러닝 알고리즘인 순환신경망(RNN)과 합성곱신경망(CNN) 방식을 사용했다. RNN은 자연어처리 연구 초기부터 사용됐던 방식으로 데이터를 순차적으로 처리하며 분석한다. 단어의 의미를 분석할 때 앞서 나온 단어를 바탕으로 이해하는 방식이다. CNN은 이미지 분석에 주로 활용되던 방식으로, 문장 내에서 단어의 순서를 보존해 각 위치에서 독립적으로 단어의 의미와 표현 방법을 분석한다.
하지만 이런 방식은 문장의 길이가 길어지면 성능이 떨어진다는 한계가 있었다. 이 때문에 트랜스포머는 어텐션 매커니즘(attention mechanism)만을 활용해 자연어를 처리하는 방식인 ‘셀프 어텐션(self-attention)’ 방식을 채택했다.
어텐션 매커니즘은 문장 전체의 중요성을 모두 분석하는 대신 중요한 부분만을 집중(attention)해 문장을 분석하는 방식이다. 더 적은 연산으로도 효율적으로 문장을 이해할 수 있다는 장점이 있다. 트랜스포머가 셀프 어텐션을 채택해 기존 방식보다 우월한 성능을 보인 이후에는 대부분 자연어처리 AI 모델에는 이 방식이 활용된다.
버트와 GPT-3는 트랜스포머에서 파생돼 만들어졌다. 이중 2018년 개발된 버트는 셀프 어텐션을 기반으로 문장을 분석하거나 생성할 때 ‘앞에서 뒤’ ‘뒤에서 앞’ 양방향으로 분석한다는 특징이 있다. 문맥을 이해하고 문장의 의미를 파악하는 데 유리하다.
GPT-3는 가장 최근인 2020년 발표됐다. GPT-3는 양방향으로 자연어를 분석하는 버트와 달리 한 방향으로 분석하는 단방향 모델이다. 상대적으로 자연어를 이해하는 성능은 부족하지만 차례로 문장을 만들어나갈 수 있어 자연어 생성에 적합하다.
이들은 방식의 차이 만큼이나 성능도 조금씩 다르다. 주재걸 KAIST AI대학원 교수는 “자연어처리 AI의 성능을 비교하기 위한 시험은 평가 방법과 조건에 따라 다양한 방식이 있다”며 “이중 대표적으로 글루 벤치마크(glue benchmark)가 있다”고 설명했다.
글루 벤치마크는 자연어처리 AI 모델을 훈련하고 성능을 평가, 비교하기 위한 9개의 데이터세트로 구성된 시험이다. 쉽게 말해 일종의 문제은행 방식인데 문법의 정확도, 두 문장의 유사도, 문장의 의미 등을 묻는 문제를 내고 AI가 이를 풀도록 한다. 대부분의 AI 모델을 평가할 수 있고 평가 결과를 시각적으로 확인할 수 있어 활용되고 있다.
글루 벤치마크를 기준으로 세 모델을 각각 평가하면 버트의 성능이 압도적으로 나온다. 실제로 글루 벤치마크 상위 10개 모델 중 4개는 버트를 기반으로 하고 있다. 트랜스포머 기반 모델도 1개가 포함됐다. 반면 대중적 유명세를 타고 있는 GPT-3는 상위 10위 안에 이름을 올리지 못했다. 글루뿐만 아니라 평가의 난이도를 보다 높인 슈퍼글루(SuperGLUE), 스쿼드(SQuAD) 등 다양한 벤치마크에서 상위권 대부분은 버트를 기반으로 하는 모델이 자리를 잡고 있다.
인간과 인공지능을 잇는 자연어처리 AI

하지만 글루 벤치마크 결과만으로 다른 AI가 열세라고 평가하긴 이르다. 모델마다 각각의 강점이 있기 때문이다. 트랜스포머의 경우 특정 언어를 다른 언어로 번역하는 ‘기계 번역’에 특화돼 있다. 버트는 자연어를 이해하는 데 특히 뛰어난 성능을 보인다. GPT-3는 자연어 생성을 목적으로 개발돼 언어 구사 능력에 뛰어나다. 사실 버트가 각종 벤치마크에서 상위권을 차지하고 GPT-3의 점수가 낮은 것도 대부분의 벤치마크가 자연어 이해 능력을 중점적으로 평가하기 때문이라는 게 전문가들의 해석이다.
주 교수는 “자연어 생성은 자연어 이해와 연관되면서도 보다 구현하기 어려운 상위 기술”이라며 “단지 벤치마크 점수를 기준으로 자연어 생성에서 뛰어난 성능을 보이는 GPT-3가 버트보다 성능이 떨어진다고 이야기하기는 어렵다”고 평가했다.
실제로 GPT-3는 벤치마크 성능과 무관하게 다양한 방면에서 활용되고 있다. 미국 채프먼대 학생은 GPT-3가 작성한 시나리오를 바탕으로 단편 영화를 제작하기도 했고, GPT-3가 직접 쓴 글이 신문기사나 칼럼으로 게재되기도 했다.
벤치마크 점수를 기준으로는 버트가 우세하지만, 자연어처리 인공지능의 연구 목적을 생각한다면 트랜스포머와 GPT-3도 각자의 강점을 갖는 셈이다.
현재 연구자들은 현존 자연어처리 AI를 뛰어넘는 보다 고성능의 모델을 개발하고 있다. 트랜스포머를 기반으로 버트와 GPT-3가 탄생했듯이, 이들을 기반으로 개발된 다양한 모델이 벤치마크에서 사람보다 뛰어나거나 근접한 점수를 받고 있다. 이미 글루 벤치마크에서는 13개의 모델이 사람보다 높은 점수를 받았고, 슈퍼글루 벤치마크에서도 사람에 근접하는 수준의 점수를 받는 모델이 꾸준히 등장하고 있다. 주 교수는 “앞으로 자연어처리 AI의 역할이 더욱 강조될 것”이라며 “궁극적으로는 모델의 강점을 모두 결합한 최적의 모델이 개발돼야 할 것”이라고 말했다.

아마존 자연어 처리 분야 베스트 셀러인 트랜스포머를 활용한 자연어처리가 출판 되었네요.
저는 트랜스포머라고 하면 자동차로봇만을 생각하고 있었는데~
이렇게 인공지능 분야에서 사용하는 자연어처리 라이브러리 라고는 생각도 못했었네요.^^
트랜스포머는 2017년에 구글 연구팀이 발표한 논문에 제안된 신경망 아키텍처로 긴 시퀀스 데이터에서 패턴을 감지하고 대용량 데이터셋을 처리하는데 뛰어난 모델으로 NLP를 넘어서 이미지 처리 등의 작업에도 사용 된다고 합니다.
이 책은 트랜스포머스 라이브러리의 개발자들과 허깅페이스의 오픈소스 개발자들이 공동 집필을 했고 박해선님이 번역을 한 트랜스포머 라이브러리와 이를 둘러싼 생태계까지 전 영역을 아우르는 책입니다.
그럼 트랜스포머를 만나러 가 보시죠~
구성
1장 : 트랜스포머 소개 및 관련 용어, 허깅페이스 생태계 소개
2장 : 감성 분석 작업에 초점을 두고 Trainer API 소개
3장 : 트랜스포머 아키텍처 설명
4장 : 다국어 텍스트에서 개체명을 인식
5장 : 텍스트를 생성하는 트랜스포머 모델의 능력을 탐구
6장 : 시퀀스-투-시퀀스 작업을 살펴 보고 이 작업에 사용하는 측정지표 살펴 보기
7장 : 리뷰 기반 질문 답변 시스템 구축
8장 : 모델 성능을 살펴 보고 지식정제,양자화,가지치기 기술을 탐색
9장 : 레이블링 된 대량의 데이터가 없을 때 모델 성능을 향상할 방법을 살펴 본다.
10장 : 파이썬 소스 코드를 자동 완성하는 모델을 밑바닥 부터 만들고 훈련하는 방법을 알려 준다.
11장 ; 트랜스포머 모델의 도전 과제와 흥미로운 신생 연구 분야를 소개한다.
서평
이 책은 파이토치를 기반으로 설명을 하였지만 텐서플로를 사용하였다고 해도 문제가 없도록 텐서플로 기반에서 어떻게 트랜스포머스를 사용하는지에 대해서 자세히 다루고 있습니다.

또한 이해하기 쉽게 필요할 때마다 그림을 삽입해서 더욱 이해도를 높여 주었습니다.
그리고 이 책은 실습 주도 방식으로 구성이 되어 있어서 직접 실습을 통해서 결과물을 눈으로 보면서 어떤 형식으로 동작하는지의 원리를 깨닫게 해 주는 구성이 좋았던 것 같습니다.
다음은 허깅페이스 허브에서 무료로 공개된 20000여개의 모델 중에서 영어를 독일어로 번역하는 모델(opus-mt-en-de)를 활용하여 단 3줄로 영어를 독일어로 번역하는 예제입니다.

코랩에서 이 세줄을 입력하여 실행을 해 보면 다음과 같이 멋지게 번역된 결과(사실 저는 번역이 완벽히 되었는지 판단을 할 수가 없다는 사실이.ㅠ.ㅠ)가 출력 됩니다.


왼쪽 입력 데이터, 오른쪽 출력데이터
또한 허깅페이스 허브에서 사전 학습된 모델을 사용하여 미세조정을 통해 자신이 원하는 모델을 만들어 내는 방법을 다루고 있기 때문에~
사전학습된 모델을 사용하여 자신에게 맞는 새로운 모델을 만들어서 실무에서 사용할 수 있는 활용을 원하시는 분들에게더욱 필요한 책이 아닐까 생각이 되네요.
또한 트랜스포머 아키텍처와 허깅페이스 생태계를 배우고 싶다면 이 책을 읽어보시면 좋을 것 같습니다.
이 책을 읽으면서 허깅페이스의 트랜스포머스 라이브러리의 자연어 처리 부분 뿐 아니라 딥러닝 전 영역으로의 영향력을 살펴 볼 수 있었던 것 같습니다.
NLP 분야에서 아마존 베스트 셀러 자리에 오른 <Natural Language Processing with Transformers>의 번역 작업을 마쳤습니다. 이 책은 최근 대세인 허깅 페이스(Hugging Face) 라이브러리를 활용하여 다양한 NLP 작업을 해결하는 방법을 소개합니다. 허깅 페이스의 머신러닝 엔지니어들이 직접 쓴 책으로도 유명하고 <핸즈온 머신러닝 2판>의 저자 오렐리앙 제롱이 직접 추천사를 쓰고 크게 칭찬한 책입니다! 자연어 처리에 관심이 모든 분에게 자신있게 추천합니다!

- 1장은 트랜스포머의 탄생을 다룹니다. 인코더-디코더, 어텐션, 전이 학습, 허깅 페이스의 트랜스포머스를 소개합니다. 간단한 파이프라인 객체를 사용해 텍스트 분류, 객체명 인식, 질문 답변, 요약, 번역, 텍스트 생성 예를 보여줍니다. 마지막으로 허깅 페이스 생태계로 허브, 토크나이저, 데이터셋, 액셀러레이트를 언급합니다.
- 2장은 emotion 데이터셋을 사용한 텍스트 분류 예제를 다루면서 본격적으로 NLP 작업에 뛰어듭니다. 허깅 페이스 데이터셋의 구조를 자세히 소개하고 여러 토큰화 방법의 장단점을 언급합니다. 그다음 DistilBERT 모델을 베이스로 사용해 헤드만 훈련하는 경우와 전체 모델을 튜닝하는 전이 학습을 각기 수행해 봅니다. 전체적으로 파이토치 기반 모델을 사용하지만 중간중간 텐서플로 모델과 케라스에 대한 안내도 빠지지 않습니다. 훈련한 뒤 오차 행렬을 사용해 모델의 예측 결과를 분석하고 마지막으로 허브에 훈련된 모델을 업로드한 후 파이프라인으로 다시 추론에 활용하는 방법까지 다루고 있습니다.
- 3장은 트랜스포머 구조를 자세히 소개합니다. 수학은 최소화하고 그림과 코드로 사용해 설명합니다. 먼저 인코더, 디코더를 포함해 트랜스포머의 전체 구조를 소개하고 인코더에 필요한 구성 요소를 하나씩 파헤칩니다. 셀프 어텐션, 멀티 헤드 어텐션, 피드 포워드, 정규화, 위치 임베딩 등입니다. 이런 요소를 직접 코드로 작성해 트랜스포머 인코더를 만듭니다. 이 과정에서 BertViz를 사용해 어텐션 가중치를 시각화해보기도 하고, 쿼리/키/값에 대한 재미있는 비유도 들을 수 있습니다. 디코더 부분은 마스킹에 대해 자세히 소개하고 다른 구성 요소 부분은 숙제로 남깁니다. 마지막으로 트랜스포머 계열의 모델을 인코더, 디코더, 인코더-디코더 유형으로 나누고 각 유형에서 마일스톤 격의 모델들을 소개합니다.
- 4장은 다국어 텍스트의 개체명 인식(NER)을 다룹니다. 이 장에서 사용하는 데이터셋인 pan-x를 둘러 보고 베이스 모델로 사용할 XLM-RoBERTa를 소개합니다. 그다음 XLM-RoBERTa의 토크나이저인 SentencePiece를 WordPiece와 비교하여 설명합니다. 또 텍스트 분류와 NER 모델의 비슷한 점과 다른 점을 설명합니다. 허깅페이스에 있는 NER 클래스를 사용하지 않고 여기서는 XLM-RoBERTa를 베이스로 NER 작업을 위한 헤드를 직접 만들어 올립니다. 이 과정에서 허깅페이스의 모델 클래스의 구조와 여러 상속 관계를 배울 수 있습니다. 만든 모델에 사전 훈련된 가중치를 로드하고 독일어 텍스트로 미세 튜닝한 다음 모델의 오류를 분석합니다. 마지막으로 독일어에서 미세 튜닝한 모델을 프랑스어, 이탈리아어, 영어 텍스트에 적용해 봅니다. 결과는 어떨까요? 이번에는 독일어와 프랑스어 데이터를 합쳐서 모델을 미세 튜닝합니다. 그다음 다시 프랑스어, 이탈리아어, 영어 텍스트에 적용해 봅니다. 결과는 어떨까요? 마지막으로 각 언어에서 미세 튜닝하고 또 전체를 합쳐서 모델을 훈련한 다음 결과를 확인합니다.
- 5장은 흥미로운 주제인 텍스트 생성 작업을 다룹니다. 이 장에서는 텍스트 생성 모델을 직접 훈련하기 보다는 유명한 GPT-2 모델을 사용해 텍스트 생성 작업에 대해 알아 봅니다. 먼저 그리디 서치와 빔 서치를 사용하여 텍스트를 생성해 보고 다양성이 높은 텍스트 생성을 위한 샘플링 방법으로 넘어가서 top-k와 top-p 방식을 배웁니다. 이 모든 방식을 허깅페이스 트랜스포머스 라이브러리에서 지원합니다. 마지막으로 최선의 텍스트 디코딩 방법에 대해 고찰하는 것으로 장을 마무리합니다.
- 6장은 요약 작업을 다룹니다. 이 장에서 사용할 데이터셋은 요약 작업에 널리 사용되는 CNN/DailyMail 데이터셋입니다. 먼저 허깅페이스의 파이프라인으로 사전 훈련된 GPT-2, T5, BART, PEGASUS 모델을 사용해 샘플 데이터의 요약을 생성하고 결과를 비교해 봅니다. 이 과정에서 네 모델의 특징도 간략히 살펴 보고 있습니다. 그다음 생성된 텍스트의 품질을 정량적으로 평가하기 위해 BLEU와 ROUGE 점수의 이론적인 부분을 소개하고 샘플 텍스트에 적용해 봅니다. 그다음 가장 성능이 뛰어난 PEGASUS 모델로 CNN/DailyMail 데이터셋의 테스트 세트 일부를 사용해 ROUGE 점수를 계산하는 방법을 알아봅니다. 마지막으로 삼성이 만든 SAMSum 데이터셋에서 PEGASUS 모델을 적용해 보고, 이 데이터셋에서 미세 튜닝한 후 결과를 비교합니다. 이 모델을 사용해 임의로 만든 샘플 대화를 요약한 결과를 보여주는 것으로 이 장을 마칩니다.
- 7장은 질문 답변(question-answering, QA) 작업을 다룹니다. 먼저 QA 작업을 간단히 소개하고 이 장에서 사용할 SubjQA 데이터셋을 준비합니다. QA 시스템을 만들기 위해 텍스트에서 가능한 답변을 찾아 내는 방법을 알아 봅니다. 이를 위해 사용할 수 있는 허깅 페이스 사전 훈련된 모델을 몇 가지 소개하고 그 중에 MiniLM을 선택합니다. 그다음 질문과 텍스트를 토큰화하고 모델에 통과시켜 출력된 결과에서 답의 범위를 찾습니다. 그다음에는 긴 텍스트를 다루기 위해 슬라이딩 윈도를 적용하는 방법을 알아 봅니다. 하지만 전체 문서에서 답을 찾기 위해서는 질문에 관련된 문서를 검색하는 시스템이 필요합니다. 이를 위해 헤이스택 라이브러리를 사용해 리트리버-리더(retriever-reader) 구조를 만듭니다. 헤이스택에서 제공하는 여러 리트리버를 소개하고 이와 같이 사용할 수 있는 문서 저장소도 알아 봅니다. 여기에서는 BM25 리트리버와 문서 저장소로 일래스틱서치를 사용합니다. 일래스틱서치를 설치하고 로컬에서 서버를 실행한 다음 SubjQA 데이터를 저장합니다. 이제 리트리버와 리더 객체를 초기화합니다. 리더는 앞에서와 같이 SQuAD에서 미세 튜닝된 MiniLM 모델입니다. 그다음 헤이스택 파이프라인으로 리트리버와 리더를 통합하여 테스트 질문에 대한 답을 추출해 봅니다. 이제 시스템 성능을 높이기 위해 리트리버와 리더를 평가할 수 있는 지표에 대해 알아 봅니다. 리트리버는 재현율을 사용해 평가합니다. 이를 위해 헤이스택의 사용자 정의 파이프라인을 만듭니다. 그다음 질문과 문서에 대해 밀집 벡터를 만들어 사용하는 DPR에 대해 알아 보고 앞서 만든 리트리버와 성능을 비교해 봅니다. 리더는 EM과 F-1 점수로 평가하며 두 지표의 장단점을 소개합니다. 마지막으로 MiniLM 모델을 SubjQA에 다시 미세 튜닝하여 전체 파이프라인의 성능을 비교해 봅니다. 추출적 QA 시스템 외에도 생성적 QA를 소개하고 헤이스택이 제공하는 RAG 모델을 사용해 질문에 대한 답변을 생성해 봅니다. 이 모든 작업을 코랩 노트북으로 테스트해 볼 수 있습니다.
- 8장은 트랜스포머 모델의 성능 개선을 위한 도구를 알아 봅니다. 먼저 여러 성능 개선 방법을 적용해 보기 위해 BERT 기반 의도 탐지 모델을 선택합니다. 의도 탐지 작업에 대한 간단한 소개와 함께 CLINC150 데이터셋에서 미세 튜닝한 BERT 모델을 허깅페이스 파이프라인으로 사용해 봅니다. 그다음 여러 방법을 적용하면서 성능, 레이턴시, 메모리 사용량을 편리하게 비교하기 위해 벤치마킹 클래스를 준비합니다. 먼저 지식 정제(knowledge distillation) 방법에 대해 자세히 설명한 다음 BERT 기반 모델로 DistilBERT 모델을 훈련합니다. 이를 위해 사용자 정의 허깅페이스 Trainer 클래스를 만듭니다. 지식 정제로 훈련된 DistilBERT 모델은 BERT 기반 모델에 비해 정확도, 레이턴시, 크기가 어떻게 다를까요? 이번에는 옵투나(Optuna)로 앞서 만든 정제 모델에 대해 하이퍼파라미터 튜닝을 수행합니다. 이 모델의 정확도, 레이턴시, 크기는 어떻게 달라졌을까요? 다음은 양자화(quantization)를 소개합니다. 기본적인 양자화 방식을 자세히 배우고 여러 양자화 방식을 소개한 후 앞서 옵투나로 최적화한 모델에 양자화를 적용해 봅니다. 양자화를 적용한 후 모델의 정확도, 레이턴시, 크기는 어떻게 달라졌을까요? 이번에는 ONNX를 사용한 최적화를 적용해봅니다. 옵투나로 최적화한 모델을 ONNX 포맷으로 바꾸어 모델의 성능을 측정합니다. 그다음 ONNX 런타임에서 제공하는 양자화를 적용한 다음 다시 성능을 측정합니다. 어떤 모델의 정확도, 레이턴시, 크기가 제일 좋을까요? 마지막으로 가중치 가지치기에 대해 소개하며 이 장을 마칩니다.
- 9장은 레이블링된 데이터가 전혀 없거나 조금만 있을 때 트랜스포머로 할 수 있는 일을 알아 봅니다. 이 장에서 사용하는 예제는 깃허브 이슈 내용을 바탕으로 적절한 태그를 다는 일입니다. 데이터셋을 준비한 다음 나이브 베이즈로 기준 모델을 만듭니다. 그다음 레이블링된 데이터가 전혀 없다고 가정하고 BERT 모델에 마스킹된 프롬프트를 주입하여 제로-샷 분류 작업을 시도해 봅니다. 이어서 자연어 추론을 위한 MNLI 데이터셋에서 훈련한 모델로 제로-샷 분류를 수행해 봅니다. 그리고 다중 레이블 분류에서 예측 레이블을 선택하는 방법을 소개합니다. 레이블링된 데이터가 적을 때는 데이터 증식을 사용할 수 있습니다. 이를 위해 NlpAug 라이브러리를 사용하여 토큰 교체를 적용하여 나이브 베이즈의 성능이 얼마나 향상되었는지 평가합니다. 그다음 방법은 텍스트 임베딩을 룩업 테이블처럼 사용해 최근접 이웃의 레이블을 예측으로 사용할 수 있습니다. 이 작업을 위해 페이스북의 FAISS 라이브러리를 사용하고 임베딩을 얻기 위해 파이썬 코드에서 훈련한 GPT-2 모델을 사용합니다. 마지막으로 레이블링된 데이터에서 트랜스포머 모델을 미세 튜닝하는 것입니다. 각 방법들의 성능을 평가하고 그래프로 비교합니다. 레이블링되지 않은 데이터가 많이 있다면 이를 활용하여 아예 언어 모델을 더 훈련할 수도 있습니다.
- 10장은 트랜스포머 모델을 직접 훈련하는 과정을 소개합니다. 이 장에서 훈련할 모델은 파이썬 코드의 앞부분을 주입하면 나머지 부분을 완성해 주는 코드 자동 완성 트랜스포머입니다. 먼저 대용량 데이터셋에 관련된 어려움을 소개하고 깃허브의 오픈소스 파이썬 코드로부터 대용량 데이터셋을 구축합니다. 이 과정에서 허깅 페이스 데이터셋의 메모리 매핑과 스트리밍 기능을 알아 봅니다. 데이터셋을 준비했으니 다음으로 토크나이저를 훈련합니다. 이를 위해 GPT-2의 토크나이저를 사용합니다. 토크나이저 훈련 방법을 배우면서 BPE 알고리즘이나 유니코드 표현을 함께 살펴봅니다. 코드 자동 완성을 위한 훈련 목표를 결정하고 하이퍼파라미터는 gpt2-xl를 그대로 사용하여 모델을 초기화합니다. 마지막으로 데이터로더를 구성하고 허깅 페이스 엑셀러레이트를 사용해 훈련 루프를 만듭니다. 그다음 모델을 훈련하고 결과를 확인합니다.
- 11장은 마지막 장으로 트랜스포머 모델을 확장할 때 어려움을 먼저 소개합니다. 그다음 어텐션 메커니즘을 효율적으로 만들기 위한 희소 어텐션과 선형 어텐션을 설명합니다. 최근 트랜스포머는 텍스트를 넘어서 비전과 음성에도 적용됩니다. iGPT, ViT와 테이블 데이터에 적용하는 TAPAS를 소개합니다. 마지막으로 멀티모달 트랜스포머로 wav2vec 2.0, VQA, LayoutLM, DALL·E, CLIP을 소개합니다. 끝으로 허깅 페이스 라이브러리를 더 많이 배울 수 있는 방법을 소개하는 것으로 책을 마칩니다.
트랜스포머 - 어텐션 메커니즘을 활용한 자연어처리 기법

본 장에서는 어텐션 메커니즘을 활용한 자연어처리 기법인 트랜스포머에 대해 알아본다.
최근 여러 NLP 작업에서 RNN 기반 시퀀스 간(seq2seq) 모델을 능가하는 트랜스포머(transformers) 아키텍처가 등장했다.
트랜스포머는 자연어 처리 분야에서 혁신적인 성능을 보이고 있으며, 언어 번역 분야에서도 좋은 성능을 보인다.
Attention helps RNNs with accessing information
어텐션 메커니즘의 개발을 이해하려면 아래 그림과 같이 전체 입력 시퀀스(예: 하나 이상의 문장)를 구문 분석하는 언어 번역 기법 seq2seq 작업에 대한 기존 RNN 모델을 생각해야 한다.

RNN이 첫 번째 출력을 생성하기 전에 전체 입력 문장을 구문 분석하는 이유는 아래와 같이 문장을 단어별로 번역하면 문법 오류가 발생할 가능성이 있기 때문이다.

seq2seq 방식의 한 가지 제한 사항은 RNN이 변환하기 전에 하나의 은닉 유닛을 통해 전체 입력 시퀀스를 기억하려고 하기 때문에 압축과정에서 긴 시퀀스의 경우 정보 손실이 발생할 수 있다.
따라서 인간이 문장을 번역하는 것과 유사하게 각 시간 단계에서 전체 입력 시퀀스에 액세스하는 것이 낫다.
일반 RNN과 달리 어텐션 메커니즘을 통해 RNN은 각 주어진 시간 단계에서 모든 입력 요소에 접근할 수 있다.
그러나 각 시간 단계에서 모든 입력 시퀀스 요소에 액세스하는 것은 힘들 수 있기 때문에, 어텐션 메커니즘은 RNN이 입력 시퀀스의 가장 관련성이 높은 요소에 집중할 수 있도록 각 입력 요소에 서로 다른 어텐션 가중치를 할당한다.
이러한 어텐션 가중치는 주어진 입력 시퀀스 요소가 주어진 시간 단계에서 얼마나 중요한지를 판단한다.
예를 들어 위 그림의 문장을 다시 보면 "mir, helfen, zu"라는 단어가 "kannst, du, Satz"라는 단어보다 출력 단어 "help"를 생성하는 데 더 적합하다.
The original attention mechanism for RNNs
주어진 입력 시퀀스 𝑥(1), 𝑥(2),…,𝑥(𝑇))에서, 어텐션 메커니즘은 각 요소 𝑥^(𝑖)(숨겨진 표현)에 가중치를 할당하고 모델이 어느 부분에 집중해야 하는지 식별하는 데 도움을 준다.
예를 들어 입력이 문장일 때 가중치가 더 큰 단어가 전체 문장을 이해하는 데 더 기여한다고 가정한다.
아래 그림에 표시된 어텐션 메커니즘이 있는 RNN은 두 번째 출력 단어를 생성하는 전체 개념을 보여줍니다.

위 그림에 나와있는 RNN 모델 2개는 아래에서 설명한다.
Processing the inputs using a bidirectional RNN
위 그림의 어텐션 기반 RNN의 첫 번째 RNN(RNN #1)은 컨텍스트 벡터 𝑐𝑖를 생성하는 양방향 RNN이다. 컨텍스트 벡터는 입력 벡터 𝑥(𝑖)의 확장 버전으로 생각할 수 있다. 즉, 𝑐𝑖 입력 벡터는 어텐션 메커니즘을 통해 다른 모든 입력 요소의 정보도 포함한다.
위 그림에서 볼 수 있듯이 RNN #2는 RNN #1에서 준비한 컨텍스트 벡터를 사용하여 출력을 생성한다.
양방향 RNN #1은 입력 시퀀스 x를 정방향(1. . . 𝑇)과 역방향(𝑇...1)으로 처리한다. 역방향으로 구문 분석하는 것은 원래 입력 시퀀스를 역순으로 하는 것과 같은 효과가 있다. 즉, 문장을 역순으로 읽는 것이다.
이렇게 하는 이유는 입력 요소가 문장의 앞이나 뒤에 오는 시퀀스 요소 또는 둘 모두에 종속될 수 있기 때문에 추가 정보를 캡처하는 것이다.
결과적으로 입력 시퀀스를 두 번(즉, 정방향 및 역방향) 읽음으로써 각 입력 시퀀스 요소에 대해 두 가지 은닉 상태를 갖게 된다. 예를 들어 두 번째 입력 시퀀스 요소 𝑥(2)의 경우 순방향 패스에서 은닉 상태 ℎ_𝐹^(2)를 얻고 역방향 패스에서 은닉 상태 ℎ_𝐵^(2)를 얻는다.
이 두 숨겨진 상태는 연결되어 최종 은닉 상태 ℎ(2)를 형성한다. 예를 들어 ℎ_𝐹^(2)와 ℎ_𝐵^(2)가 모두 128차원 벡터인 경우 연결된 은닉 상태 ℎ(2)는 256개의 요소로 구성된다.
이 연결된 은닉 상태는 j번째 단어의 정보를 양방향으로 포함하므로 소스 단어의 "주석"으로 간주할 수 있다.
Generating output from context vectors
위 그림에서 RNN #2를 출력을 생성하는 기본 RNN으로 간주할 수 있다. 은닉 상태로 구성된 컨텍스트 벡터를 입력으로 받는다.
컨텍스트 벡터 𝑐𝑖는 이전 하위 섹션의 RNN #1에서 얻은 연결된 은닉 상태인 ℎ(1) … ℎ(𝑇)에 어텐션 가중치를 적용한 벡터다.
i번째 입력의 컨텍스트 벡터를 가중치 합으로 계산하는 것은 다음과 같다.

여기서 𝛼𝑖j는 i번째 입력 시퀀스 요소의 맥락에서 입력 시퀀스 𝑗=1...T에 대한 어텐션 가중치를 나타낸다. 각 i번째 입력 시퀀스 요소에는 고유한 어텐션 가중치 세트가 존재한다.
일반적인 RNN과 마찬가지로 RNN #2도 은닉 상태를 사용한다.
앞서 언급한 "주석"과 최종 출력 사이의 은닉 레이어를 고려하여 시간 𝑖의 은닉 상태를 s(i)로 표시한다.
RNN #2는 각 단계 i에서 앞서 언급한 컨텍스트 벡터 𝑐𝑖를 입력으로 받는다.
위 그림에서 은닉 상태 𝑠^𝑖가 이전 은닉 상태 𝑠^𝑖-1, 이전 타겟 단어 𝑦^𝑖-1, 및 컨텍스트 벡터 𝑐𝑖에 따라 달라지는 것을 알 수 있고, 이는 시간 i에서 대상 단어 𝑦𝑖에 대한 예측 출력 𝑜𝑖를 생성하는 데 사용된다.
시퀀스 벡터 𝒚는 학습 중에 사용할 수 있는 입력 시퀀스 𝒙의 올바른 변환을 나타내는 시퀀스 벡터다.
학습 중에 실제 레이블 𝑦^𝑖은 다음 상태인 𝑠^𝑖+1로 주입된다. 이 실제 레이블 정보는 예측(추론)에 사용할 수 없으므로 이전 그림에 표시된 대로 예측 출력 𝑜^i를 제공한다.
위에서 논의한 내용을 요약하면 어텐션 기반 RNN은 두 개의 RNN으로 구성된다. RNN #1은 입력 시퀀스 요소에서 컨텍스트 벡터를 준비하고 RNN #2는 컨텍스트 벡터를 입력으로 받는다.
컨텍스트 벡터는 입력에 대한 가중치 합계를 통해 계산되며 여기서 가중치는 어텐션 가중치 𝛼𝑖j다.
Computing the attention weights
어텐션 가중치에 대해 알아본다. 어텐션 가중치는 입력(annotations)와 출력(contexts)을 쌍으로 연결하기 때문에 각 어텐션 가중치 𝛼𝑖j에는 두 개의 첨자가 있다. 여기서 j는 입력의 인덱스 위치를 나타내고 i는 출력 인덱스 위치에 해당한다.
어텐션 가중치 𝛼𝑖j는 정렬 점수 e𝑖j의 정규화 버전이며, 여기서 정렬 점수는 위치 j 주변의 입력이 위치 i의 출력과 얼마나 잘 일치하는지 평가한다.
구체적으로 다음과 같이 정렬 점수를 정규화하여 어텐션 가중치를 계산한다.

이 방정식은 softmax 함수와 유사하며, 결과적으로 어텐션 가중치 𝛼𝑖1... 𝛼𝑖t의 합은 1이 되지 않는다.
어텐션 기반 RNN 모델을 세 부분으로 구성할 수 있다.
첫 번째 부분은 입력의 양방향으로 연결된 은닉 상태를 계산하고, 두 번째 부분은 입력으로 컨텍스트 벡터를 사용한 순환 블록으로 구성된다. 마지막 부분은 각 입력 및 출력 요소 쌍 간의 관계를 설명하는 어텐션 가중치 및 컨텍스트 벡터의 계산과 관련이 있다.
트랜스포머 아키텍처는 어텐션 메커니즘도 활용하지만 어텐션 기반 RNN과 달리 self-attention mechanism에만 의존하고 RNN에서 발견되는 반복 프로세스를 포함하지 않는다.
즉, 트랜스포머 모델은 한 번에 한 요소씩 시퀀스를 읽고 처리하기보다, 전체 입력 시퀀스를 한 번에 모두 처리한다.
Introducing the self-attention mechanism
self-attention 메커니즘은 우리가 이전 섹션에서 논의한 어텐션 메커니즘의 다른 종류일 뿐이다. 앞서 논의한 어텐션 메커니즘은 두 개의 서로 다른 모듈, 즉 RNN의 인코더와 디코더를 연결하는 작업으로 생각할 수 있다.
self-attention은 입력에만 초점을 맞추고 입력 요소 간의 종속성만 캡처한다. 이는 즉, 두 개의 모듈을 연결하지 않음을 의미한다.
아래 첫 번째 하위 섹션에서는 학습 매개변수가 없는 기본 형태의 self-attention을 소개한다.
그 다음 두 번째 하위 섹션에서는 트랜스포머 아키텍처에서 사용되며 학습 가능한 매개변수를 포함하는 일반적인 self-attention 버전을 소개한다.
Starting with a basic form of self-attention
아래 섹션에서는 셀프 어텐션을 소개하기 위해 길이 T의, 𝒙(1),…,𝒙(𝑇)의 입력 시퀀스와 출력 시퀀스 𝒛(1), 𝒛(2) ,…,Z(T)를 갖는다고 가정한다.
설명에서의 혼란을 피하기 위해 전체 트랜스포머 모델의 최종 출력으로 o를 사용하고 모델의 중간 단계의 self-attention 레이어의 출력으로 𝒛를 사용한다.
이러한 시퀀스의 각 i번째 요소인 𝒙(𝑖) 및 𝒛(𝑖)는 위치 i의 입력에 대한 특징 정보를 나타내는 크기 d(즉, 𝒙(𝑖) ∈ 𝑅^𝑑)의 벡터이며 이는 일반적인 RNN과 유사하다.
그런 다음 seq2seq 작업에서 self-attention의 목표는 다른 모든 입력 요소에 대한 현재 입력 요소의 종속성을 모델링하는 것이다.
이를 달성하기 위해 Self-attention 메커니즘은 세 단계로 구성된다.
- 시퀀스의 현재 요소와 다른 모든 요소 간의 유사성을 기반으로 중요도 가중치를 도출한다.
- softmax 함수를 사용하여 가중치를 정규화한다.
- 이 가중치를 해당 시퀀스 요소와 함께 사용하여 어텐션 값을 계산한다.
좀 더 형식적으로 표현하자면, self-attention의 출력 𝒛(𝑖)은 모든 T 입력 시퀀스 𝒙(𝑗)의 가중 합이다(𝑗= 1...T).
예를 들어 i번째 입력 요소의 경우 해당 출력 값은 다음과 같이 계산된다.

따라서 우리는 𝒛(𝑖)를 입력 벡터 𝒙(𝑖)의 컨텍스트 인식 임베딩 벡터로 생각할 수 있다. 이는 각 어텐션 가중치로 가중된 다른 모든 입력 시퀀스 요소를 포함한다.
여기서 어텐션 가중치 𝛼𝑖j는 현재 입력 요소 𝒙𝑖와 입력 시퀀스 𝒙(1)...𝒙(𝑇)의 다른 모든 요소 간의 유사성을 기반으로 계산된다.
보다 구체적으로, 이 유사성은 다음 단락에서 설명하는 두 단계로 계산된다.
먼저 현재 입력 요소 𝒙(𝑖)와 입력 시퀀스의 다른 요소 𝒙(𝑗) 사이의 내적을 계산한다.

어텐션 가중치 a𝑖j를 얻기 위해 ω𝑖j 값을 정규화하기 전에 코드 예제를 통해 ω𝑖j 값을 계산하는 방법에 대해 알아본다.
여기에서는 can you help me to translate this sentence라는 문장이 있다고 가정한다.
>>> import torch
>>> sentence = torch.tensor(
>>> [0, # can
>>> 7, # you
>>> 1, # help
>>> 2, # me
>>> 5, # to
>>> 6, # translate
>>> 4, # this
>>> 3] # sentence
>>> )
>>> sentence
tensor([0, 7, 1, 2, 5, 6, 4, 3])임베딩 레이어를 통해 이 문장을 실수 벡터 표현으로 이미 인코딩했다고 가정한다. 여기서 임베딩 크기는 16이고 사전 크기는 10이다.
다음 코드는 8개 단어의 단어 임베딩을 생성한다.
>>> torch.manual_seed(123)
>>> embed = torch.nn.Embedding(10, 16)
>>> embedded_sentence = embed(sentence).detach()
>>> embedded_sentence.shape
torch.Size([8, 16])이제 i번째 단어 임베딩과 j번째 단어 임베딩 간의 내적으로 ω𝑖j를 계산할 수 있다.
다음과 같이 모든 ω𝑖j 값에 대해 이를 수행한다.
>>> omega = torch.empty(8, 8)
>>> for i, x_i in enumerate(embedded_sentence):
>>> for j, x_j in enumerate(embedded_sentence):
>>> omega[i, j] = torch.dot(x_i, x_j)Attention is all we need: introducing the original transformer architecture
트랜스포머 아키텍처는 RNN에서 처음 사용된 어텐션 메커니즘을 기반으로 한다. 원래 어텐션 메커니즘을 사용하는 의도는 긴 문장으로 작업할 때 RNN의 텍스트 생성 기능을 개선하는 것이었다.
그러나 RNN에 대한 어텐션 메커니즘을 실험한 지 불과 몇 년 만에 연구자들은 어텐션 기반 언어 모델이 반복 레이어가 삭제되었을 때 훨씬 더 강력하다는 것을 발견했고, 이를 이용하여 현재의 트랜스포머 아키텍처가 개발되었다.
self-attention 메커니즘 덕분에 트랜스포머 모델은 자연어처리 컨텍스트에서 입력 시퀀스의 요소 간의 장거리 종속성을 캡처할 수 있었고, 모델이 입력 문장의 의미를 더 잘 "이해"하는 데 도움을 주었다.
이 트랜스포머 아키텍처는 원래 언어 번역을 위해 설계되었지만 영어 구성 구문 분석, 텍스트 생성 및 텍스트 분류와 같은 다른 작업으로 일반화할 수 있다.
나중에 이 원래 트랜스포머 아키텍처에서 파생된 BERT 및 GPT와 같은 인기 있는 언어 모델에 대해 설명한다.
아래 그림은 트랜스포머의 주요 아키텍처와 구성 요소를 보여준다.

다음 섹션에서는 트랜스포머 모델을 인코더와 디코더의 두 가지 블록으로 분해하여 단계별로 살펴본다.
인코더는 원본 순차 입력을 수신하고 멀티 헤드 셀프 어텐션 모듈을 사용하여 임베딩을 인코딩한다. 디코더는 처리된 입력을 받고 마스킹된 형태의 self-attention을 사용하여 결과 시퀀스(예: 번역된 문장)를 출력한다.
Encoding context embeddings via multi-head attention
인코더 블록의 전반적인 목표는 순차 입력 𝑿 = (𝒙(1), 𝒙(2),…,𝒙(𝑇))을 받아 연속 표현 𝒁=𝒛(1), 𝒛( 2),…, 𝒛(𝑇))을 디코더로 전달하는 것이다.
인코더는 6개의 동일한 레이어로 구성된 스택이다. 여기에서 6은 트랜스포머 논문에서 선택한 하이퍼파라미터이며, 모델 성능에 따라 레이어 수를 조정할 수 있다.
이러한 각 동일한 레이어 내부에는 두 개의 하위 레이어가 있다. 하나는 Multi-head attention을 계산하며, 다른 하나는 이전 장에서 이미 접한 완전 연결 레이어다.
아래에서는 멀티 헤드 어텐션에 대해 먼저 알아본다.
확장된 내적 어텐션에서 입력 시퀀스를 변환하기 위해 3개의 행렬을 사용한다. 멀티 헤드 어텐션의 맥락에서는 세 개의 매트릭스 세트를 하나의 어텐션 헤드로 생각할 수 있습니다.
이름에서 알 수 있듯이 다중 헤드 어텐션에서는 컨볼루션 신경망이 여러 개의 커널을 가질 수 있는 방식과 유사한 헤드(쿼리, 값 및 키 매트릭스 세트)가 여러 개 있다.
'인공지능(AI)' 카테고리의 다른 글
| 요즘 엔비디아에 무슨 일이? 엔비디아 폭등의 '진짜' 이유(ft.AI 붐) (0) | 2023.06.09 |
|---|---|
| 연구 표본수 산출 방법(G*power test) (1) | 2023.06.08 |
| 챗GPT가 촉발한 AI 혁명, 급변하는 흐름 읽기 [또 진화한 GPT-4의 위력과 핵심기술] (0) | 2023.06.05 |
| 챗GPT 플러그인 사용법 총정리 (0) | 2023.06.03 |
| 블로그 마케팅을 포기하면 안되는 7가지 이유 - AI 활용법 [콘텐츠 마케터의 잃어버린 시간을 찾아서] (0) | 2023.05.27 |



